How to Scrape a Website Without Getting Blocked
Many companies today use parsing for many important benefits. Whether you are an online trader or just want to provide services to other companies, collecting data can be a way to increase your bottom line.
However, many companies that may employ a large number of programmers or system administrators do not see manual parsing as a desirable activity. The fact is that sending a large number of requests for resources can block the operation of the site.
If you want to know how to crawl a website without getting blocked read this article.
Is scraping a website illegal?
Automatically obtaining open information from a website is legal.
Website scraping is just a collection of what we can see with our own eyes on the site and copy it by hand. Thus, only actions with already collected information, that is, actions of the customer himself, can fall under the copyright article. It's just that a person does it for a long time, slowly and with errors, and the parser does it quickly and doesn’t make mistakes.
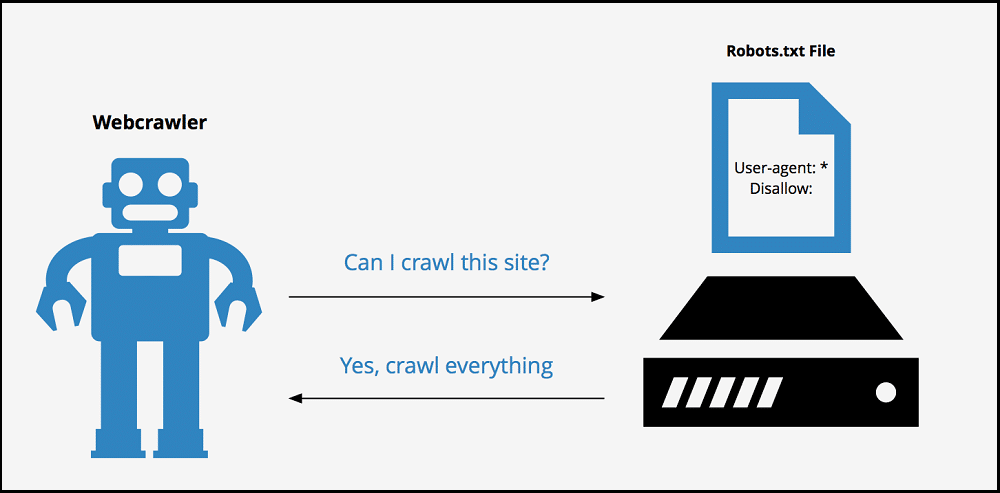
Can websites detect scraping?
Bots that are used by you without understanding how to crawl sites without blocking are often instantly blocked. Increasing site traffic due to bots during parsing looks harmless. However, bots can send significantly more requests per second than the average user and can put a heavy load on the servers that host the site. If it crosses a certain threshold, the site may become too slow or shut down completely.
For many, a website is just one link in a revenue-generating chain. Parser bots and various crawlers can send too many requests and put such a load on the servers that this can lead to the closure of the site. Even small delays can cost potential income from customers, since no user will be satisfied with this situation, then they can simply close this site and buy the desired product from a competitor. Thus, many sites use anti-parsing technologies to avoid any possible slowdowns that bots might cause.
Some various algorithms and specifications differentiate between users and bot users. CAPTCHA and reCAPTCHA are the most popular anti-bot systems. A new version of reCAPTCHA 3 has been released and it is even more effective in detecting bots.
Other solutions can track the number of requests from a single IP address. This is especially true with periodic monitoring of prices. Some analyzers can match the location of your IP address with your language and time zone and detect inconsistencies.
How to avoid being blacklisted while scraping?
Blocks can be avoided by understanding how sites protect themselves. There’re very specific methods and technologies that can help you collect data from large marketplaces, for example, without banning, blocking, or even detecting using parsers. We’ll tell you, how to scrape websites without getting blocked.
Rotate IP addresses
Proxy Rotator is a tool that takes IP addresses in your proxy's IP pool and randomly assigns them to your computer. This is one of the best ways to avoid blocks and scrape website data as it allows your bots to send hundreds of requests from random IP addresses and different geographic locations. It isn’t possible to detect you, and in the case of blocking individual addresses, you will not lose the entire pool of addresses. Be sure to figure out the reasons for blocking so as not to make mistakes in the future. The most common is the frequency of requests over time, adjust this wisely.
Avoid image scraping
Images are objects with a significant amount of data. They can be copyrighted. In addition, images are often hidden in JavaScript elements (for example, behind lazy loading), which greatly increases the complexity of the data collection process and slows down the parser. This inevitably leads to blocking.
Avoid JavaScript
It’s difficult to get the data in the JavaScript elements. Besides, JavaScript can cause many other problems: memory leaks, application instability or, sometimes, complete crashes. Dynamic functions can often be a burden. Avoid JavaScript using without necessity.
Avoid Honeypot Traps
A honeypot trap is a link in the HTML code. They are invisible to regular users, but experienced parsers can detect them. Only robots can follow such a link.
This method requires a lot of time and effort. But if your request was blocked, then it’s most likely due to the action of a honeypot trap.
Change the crawling pattern
Your search robot moves through the site according to a certain pattern. If you use the same scan pattern all the time, then you will be blocked. It's just a matter of time.
Add additional mouse movements, scrolling, and clicks. Put yourself in the shoes of a regular user. Think about what movements he will use, and then apply the information to the tool. For example, a bot can visit the home page first and then make requests to the internal pages.
Check robots exclusion protocol
Before crawling a website's data, please check your target allows data collection. Be sure to check the Robots Exclusion Protocol file (robots.txt).
It's very important to follow the rules. Even if the web page allows crawling, please follow the online etiquette:
- be respectful and do not harm;
- scan the page during off-peak hours;
- don’t allow a large number of requests to come from one IP address;
- be sure to set a delay between requests.
Crawl during off-peak hours
The vast majority of bots navigate web pages much faster than a regular user. After all, no crawlers read content. This can lead to a significant load on the server, deterioration of the site, discomfort for users.
The best time to crawl an information website is after midnight. This’s a really good idea for gathering information.
Detect Website Changes
Sometimes the structure of the site can change. This isn’t the most budgetary and productive, but nevertheless a common way to deal with crawling. Before starting scraping, make sure there have been no changes to the website.
Reduce the scraping speed
To reduce the risk of possible blockage, reduce the scrolling speed. Add random breaks between requests, program commands to wait before taking a certain action.
Use real user agents
Most modern servers are very advanced. They can parse HTTP request headers called user agents. They contain a variety of information, which includes both operating system data and application versions.
If the server considers the user agents to be suspicious, it will block them. Common user agents contain several popular configurations. Make sure that the HTTP requests you use look like regular ones.
It is equally important to use the most common and modern user agents. If you are working with a 5-year-old program, it will immediately raise suspicions.
Set a Referrer
The site can find out where you came from by using the referrer header. We recommend that you configure it so that it looks like you came from Google.
"Referer": "https://www.google.com/"
Be sure to adapt your request to your geographic region. This will make scrawling web data even more secure.
Set Other Request Headers
Popular web browsers have several sets of headers, each of which is checked by sites. This is another way to block web scrapers.
You should give your parser a real look. To do this, copy the custom browser headers. Settings such as Accept, Accept-Encoding, Accept-Language, and Upgrade-Insecure-Requests will make your requests look like they are coming from a real browser, so you don't get blocking of web pages.
Set Random Intervals In Between Your Requests
The simplest thing to do is to set delays between requests to someone else's site.
The delays are set using the PHP sleep function, which takes the time in seconds as a parameter — for this time the script simply "sleeps", and then its execution starts over.
Important: set uneven delays, otherwise a script that sends requests with a frequency of, for example, exactly 5 seconds, is easily tracked and banned. Also, the delay time for each site should be selected individually.
Set your fingerprint right
The defense mechanisms against website scraping are becoming more and more advanced. Some resources use Transmission Control Protocol (TCP) or IP Fingerprint to detect bots.
During the scan, TCP leaves certain parameters. They are installed by the user's operating system or device. If you do not want your resource to be banned during the scraping process, check the consistency of the parameters. Litport proxies have the most correct TCP fingerprints from real mobile devices.
Use a CAPTCHA Solving Service
Most of the time, captchas are displayed only if the IP address is suspicious, so proxy switching will work in such cases. Otherwise, you need to use the captcha solving service.
It should be remembered that although some CAPTCHAs can be solved automatically using Optical Character Recognition (OCR), the most recent one must be solved manually.
Use a headless browser
One of the good tools for scraping data from a webpage is the headless browser. It works like any other browser, except that such a browser does not have a graphical user interface (GUI).
With its help, you can quickly clear the content that is loaded using the rendering of JavaScript elements. The most widely used web browsers, Chrome and Firefox, have headless mode.
Use a proxy server
Proxies are the main tool for scraping website data. If you decide to use proxy servers to get data from more complex sites, be sure to choose a reliable proxy provider. Top providers like LitPort use top-notch IT infrastructure, security, and encryption technologies to ensure consistent bandwidth and uptime. Any downtime of proxy servers causes problems and delays, take it seriously.
Plus, with a trusted proxy provider, you will have access to customer support and professional assistance with implementing proxies in your day-to-day parsing operations. This can be very useful when you want to upgrade or downgrade your activities while avoiding the risk of being blocked by websites.
Also, good proxy providers should support features such as fixed port entries, session time management, and a wide variety of possible locations. Certain content may only be displayed in certain regions or countries (for example, the United States). In this case, the use of a US proxy server will allow the collection of any data content.
How do you stop a website from being scraped?
You can provide technical protection of your site from parsing. Among the most advanced methods of blocking web scraping:
- blocking IP addresses;
- use captcha;
- install invisible captcha;
- install email verification;
- change the structure of the site from time to time, but this will lead to a significant investment of time and money.
Conclusion
Now you know the answers to the question of how to parse without blocking. As you can see, there are good reasons for sites to block parsers. Fortunately, there are many ways to get around these locks. Use the many advantages of Litport and enjoy doing business on the Internet.
James Sanders
James joined litport.net since very early days of our business. He is an automation magician helping our customers to choose the best proxy option for their software. James's goal is to share his knowledge and get your business top performance.